

WayBack Archive ha costruito un mega archivio web che è in grado di risalire alla struttura di un sito web fino al 1996 ovvero gli albori del web così come lo conosciamo.
Ma come funziona nel concreto questo archivio web? In buona sostanza nel corso degli anni i crawler scattano delle istantanee al nostro sito web creando una cache che anche oggi possiamo vedere su google all'interno delle SERP. Questi dati sono stati immagazzinati da WebArchive, molti dei quali provengono da Alexa Crawler e li ha inseriti all'interno di un archivio web in modo tale da poter tenere la cronistoria di ogni sito web in base a come è stato visto durante il crawling dei motori di ricerca.
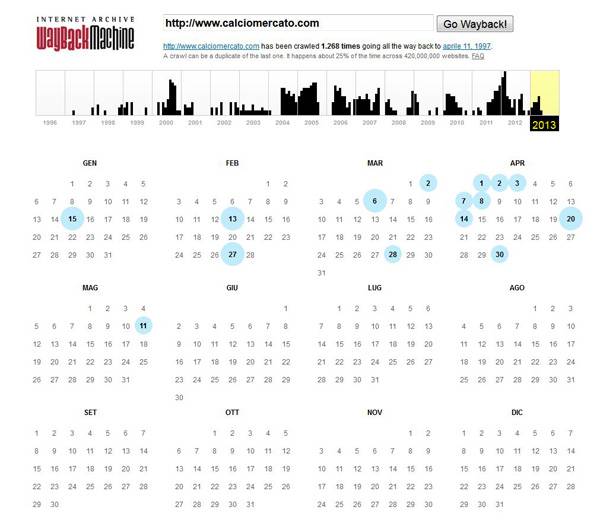
Lo strumento può essere molto utile sia per chi è appassionato di web vintage e nostalgici che vogliono scoprire come si è evoluto il loro sito web preferito nel corso degli anni (devo ammettere che il primo test che ho fatto è stato su calciomercato.com, il primo sito web che ho visitato quando ho avuto a disposizione una connessione internet a 36k a casa mia).
WebArchive tuttavia può anche essere un ottimo strumento professionale per risalire a dati web che altrimenti potrebbero essere perduti, capire com'era strutturato un sito web di un cliente e quali modifiche sono state svolte nel corso del tempo dai nostri predecessori.
Per visualizzare le varie versioni del sito web vi sarà sufficiente dopo aver inserito l'indirizzo nella barra di ricerca selezionare i vari pallini nel calendario nei quali è posta una cache del sito.
Spero che Webarchive possa tornare utile a tutti voi come lo è stato per me oppure possa allietare le vostre pause in un nostalgico wayback web alla riscoperta dei vostri siti web preferiti e come essi sono cambiati nel tempo, magari davanti ad una tazza di Thè o del buon vino rosso!
Scopri WebArchive!